RAID
RAID (an acronym for redundant array of independent disks; originally redundant array of inexpensive disks[1][2]) is a storage technology that combines multiple disk drive components into a logical unit. Data is distributed across the drives in one of several ways called "RAID levels", depending on what level of redundancy and performance (via parallel communication) is required.
RAID is an example of storage virtualization and was first defined by David A. Patterson, Garth A. Gibson, and Randy Katz at the University of California, Berkeley in 1987.[3] Marketers representing industry RAID manufacturers later attempted to reinvent the term to describe a redundant array of independent disks as a means of dissociating a low-cost expectation from RAID technology.[4]
RAID is now used as an umbrella term for computer data storage schemes that can divide and replicate data among multiple physical drives. The physical drives are said to be in a RAID,[5] which is accessed by the operating system as one single drive. The different schemes or architectures are named by the word RAID followed by a number (e.g., RAID 0, RAID 1). Each scheme provides a different balance between two key goals: increase data reliability and increase input/output performance.
Standard levels
A number of standard schemes have evolved which are referred to as levels. There were five RAID levels originally conceived, but many more variations have evolved, notably several nested levels and many non-standard levels (mostly proprietary). RAID levels and their associated data formats are standardised by SNIA in the Common RAID Disk Drive Format (DDF) standard.
Following is a brief textual summary of the most commonly used RAID levels.[6]
-
- RAID 0 (block-level striping without parity or mirroring) has no (or zero) redundancy. It provides improved performance and additional storage but no fault tolerance. Hence simple stripe sets are normally referred to as RAID 0. Any drive failure destroys the array, and the likelihood of failure increases with more drives in the array (at a minimum, catastrophic data loss is almost twice as likely compared to single drives without RAID). A single drive failure destroys the entire array because when data is written to a RAID 0 volume, the data is broken into fragments called blocks. The number of blocks is dictated by the stripe size, which is a configuration parameter of the array. The blocks are written to their respective drives simultaneously on the same sector. This allows smaller sections of the entire chunk of data to be read off each drive in parallel, increasing bandwidth. RAID 0 does not implement error checking, so any error is uncorrectable. More drives in the array means higher bandwidth, but greater risk of data loss.
-
- In RAID 1 (mirroring without parity or striping), data is written identically to multiple drives, thereby producing a "mirrored set"; at least 2 drives are required to constitute such an array. While more constituent drives may be employed, many implementations deal with a maximum of only 2; of course, it might be possible to use such a limited level 1 RAID itself as a constituent of a level 1 RAID, effectively masking the limitation. The array continues to operate as long as at least one drive is functioning. With appropriate operating system support, there can be increased read performance, and only a minimal write performance reduction; implementing RAID 1 with a separate controller for each drive in order to perform simultaneous reads (and writes) is sometimes called multiplexing (or duplexing when there are only 2 drives).
-
- In RAID 2 (bit-level striping with dedicated Hamming-code parity), all disk spindle rotation is synchronized, and data is striped such that each sequential bit is on a different drive. Hamming-code parity is calculated across corresponding bits and stored on at least one parity drive.
-
- In RAID 3 (byte-level striping with dedicated parity), all disk spindle rotation is synchronized, and data is striped so each sequential byte is on a different drive. Parity is calculated across corresponding bytes and stored on a dedicated parity drive.
-
- RAID 4 (block-level striping with dedicated parity) is identical to RAID 5 (see below), but confines all parity data to a single drive. In this setup, files may be distributed between multiple drives. Each drive operates independently, allowing I/O requests to be performed in parallel. However, the use of a dedicated parity drive could create a performance bottleneck; because the parity data must be written to a single, dedicated parity drive for each block of non-parity data, the overall write performance may depend a great deal on the performance of this parity drive.
-
- RAID 5 (block-level striping with distributed parity) distributes parity along with the data and requires all drives but one to be present to operate; the array is not destroyed by a single drive failure. Upon drive failure, any subsequent reads can be calculated from the distributed parity such that the drive failure is masked from the end user. However, a single drive failure results in reduced performance of the entire array until the failed drive has been replaced and the associated data rebuilt. Additionally, there is the potentially disastrous RAID 5 write hole.
-
- RAID 6 (block-level striping with double distributed parity) provides fault tolerance of two drive failures; the array continues to operate with up to two failed drives. This makes larger RAID groups more practical, especially for high-availability systems. This becomes increasingly important as large-capacity drives lengthen the time needed to recover from the failure of a single drive. Single-parity RAID levels are as vulnerable to data loss as a RAID 0 array until the failed drive is replaced and its data rebuilt; the larger the drive, the longer the rebuild takes. Double parity gives additional time to rebuild the array without the data being at risk if a single additional drive fails before the rebuild is complete.
The following table provides an overview of the most important parameters of standard RAID levels. In each case:
- Array space efficiency is given as an expression in terms of the number of drives,
 ; this expression designates a value between 0 and 1, representing the fraction of the sum of the drives' capacities that is available for use. For example, if 3 drives are arranged in RAID 3, this gives an array space efficiency of
; this expression designates a value between 0 and 1, representing the fraction of the sum of the drives' capacities that is available for use. For example, if 3 drives are arranged in RAID 3, this gives an array space efficiency of 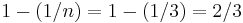 (approximately 66%); thus, if each drive in this example has a capacity of 250 GB, then the array has a total capacity of 750 GB but the capacity that is usable for data storage is only 500 GB.
(approximately 66%); thus, if each drive in this example has a capacity of 250 GB, then the array has a total capacity of 750 GB but the capacity that is usable for data storage is only 500 GB. - Array failure rate is given as an expression in terms of the number of drives, , and the drive failure rate,
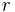 (which is assumed to be identical and independent for each drive). For example, if each of 3 drives has a failure rate of 5% over the next 3 years, and these drives are arranged in RAID 3, then this gives an array failure rate of
(which is assumed to be identical and independent for each drive). For example, if each of 3 drives has a failure rate of 5% over the next 3 years, and these drives are arranged in RAID 3, then this gives an array failure rate of 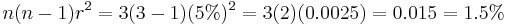 over the next 3 years.
over the next 3 years.
| Level | Description | Minimum # of drives | Space Efficiency | Fault Tolerance | Array Failure Rate** | Read Benefit | Write Benefit | Image |
|---|---|---|---|---|---|---|---|---|
| RAID 0 | Block-level striping without parity or mirroring. | 2 | 1 | 0 (none) | 1−(1−r)n | nX | nX | |
| RAID 1 | Mirroring without parity or striping. | 2 | 1/n | n−1 drives | rn | nX | 1X | |
| RAID 2 | Bit-level striping with dedicated Hamming-code parity. | 3 | 1 − 1/n ⋅ log2(n-1) | RAID 2 can recover from 1 drive failure or repair corrupt data or parity when a corrupted bit's corresponding data and parity are good. | variable | variable | variable | |
| RAID 3 | Byte-level striping with dedicated parity. | 3 | 1 − 1/n | 1 drive | n(n−1)r2 | (n−1)X | (n−1)X* | |
| RAID 4 | Block-level striping with dedicated parity. | 3 | 1 − 1/n | 1 drive | n(n−1)r2 | (n−1)X | (n−1)X* | |
| RAID 5 | Block-level striping with distributed parity. | 3 | 1 − 1/n | 1 drive | n(n−1)r2 | (n−1)X* | (n−1)X* | |
| RAID 6 | Block-level striping with double distributed parity. | 4 | 1 − 2/n | 2 drives | n(n-1)(n-2)r3 | (n−2)X* | (n−2)X* |
* Assumes hardware is fast enough to support; ** Assumes independent, identical rate of failure amongst drives
Nested (hybrid) RAID
In what was originally termed hybrid RAID,[7] many storage controllers allow RAID levels to be nested. The elements of a RAID may be either individual drives or RAIDs themselves. Nesting more than two deep is unusual.
As there is no basic RAID level numbered larger than 9, nested RAIDs are usually unambiguously described by attaching the numbers indicating the RAID levels, sometimes with a "+" in between. The order of the digits in a nested RAID designation is the order in which the nested array is built: For a RAID 1+0, drives are first combined into multiple level 1 RAIDs that are themselves treated as single drives to be combined into a single RAID 0; the reverse structure is also possible (RAID 0+1).
The final RAID is known as the top array. When the top array is a RAID 0 (such as in RAID 1+0 and RAID 5+0), most vendors omit the "+" (yielding RAID 10 and RAID 50, respectively).
- RAID 0+1: striped sets in a mirrored set (minimum four drives; even number of drives) provides fault tolerance and improved performance but increases complexity.
- The key difference from RAID 1+0 is that RAID 0+1 creates a second striped set to mirror a primary striped set. The array continues to operate with one or more drives failed in the same mirror set, but if drives fail on both sides of the mirror the data on the RAID system is lost.
- RAID 1+0: (a.k.a. RAID 10) mirrored sets in a striped set (minimum four drives; even number of drives) provides fault tolerance and improved performance but increases complexity.
- The key difference from RAID 0+1 is that RAID 1+0 creates a striped set from a series of mirrored drives. The array can sustain multiple drive losses so long as no mirror loses all its drives.[8]
- RAID 5+1: mirrored striped set with distributed parity (some manufacturers label this as RAID 53).
Whether an array runs as RAID 0+1 or RAID 1+0 in practice is often determined by the evolution of the storage system. A RAID controller might support upgrading a RAID 1 array to a RAID 1+0 array on the fly, but require a lengthy offline rebuild to upgrade from RAID 1 to RAID 0+1. With nested arrays, sometimes the path of least disruption prevails over achieving the preferred configuration.
RAID Parity
Many RAID levels employ an error protection scheme called "parity". Most use the simple XOR parity described in this section, but RAID 6 uses two separate parities based respectively on addition and multiplication in a particular Galois Field[9] or Reed-Solomon error correction. XOR parity calculation is a widely used method in information technology to provide fault tolerance in a given set of data.
In Boolean logic, there is an operation called exclusive or (XOR), meaning "one or the other, but not neither and not both," that is:
0 XOR 0 = 0 0 XOR 1 = 1 1 XOR 0 = 1 1 XOR 1 = 0
The XOR operator is central to how parity data is created and used within an array. It is used both for the protection of data, as well as for the recovery of missing data.
As an example, consider a simple RAID made up of 6 drives (4 for data, 1 for parity, and 1 for use as a hot spare), where each drive has only a single byte worth of storage (a '-' represents a bit, the value of which doesn't matter at this point in the discussion):
Drive #1: -------- (Data) Drive #2: -------- (Data) Drive #3: -------- (Data) Drive #4: -------- (Data) Drive #5: -------- (Hot Spare) Drive #6: -------- (Parity)
Let the following data be written to the data drives:
Drive #1: 00101010 (Data) Drive #2: 10001110 (Data) Drive #3: 11110111 (Data) Drive #4: 10110101 (Data) Drive #5: -------- (Hot Spare) Drive #6: -------- (Parity)
Every time data is written to the data drives, a parity value is calculated in order to be able to recover from a data drive failure. To calculate the parity for this RAID, a bitwise XOR of each drive's data is calculated as follows, the result of which is the parity data:
00101010 XOR 10001110 XOR 11110111 XOR 10110101 = 11100110
The parity data 11100110 is then written to the dedicated parity drive:
Drive #1: 00101010 (Data) Drive #2: 10001110 (Data) Drive #3: 11110111 (Data) Drive #4: 10110101 (Data) Drive #5: -------- (Hot Spare) Drive #6: 11100110 (Parity)
Suppose Drive #3 fails. In order to restore the contents of Drive #3, the same XOR calculation is performed using the data of all the remaining data drives and (as a substitute for Drive #3) the parity value (11100110) stored in Drive #6:
00101010 XOR 10001110 XOR 11100110 XOR 10110101 = 11110111
With the complete contents of Drive #3 recovered, the data is written to the hot spare, and the RAID can continue operating.
Drive #1: 00101010 (Data) Drive #2: 10001110 (Data) Drive #3: --Dead-- (Data) Drive #4: 10110101 (Data) Drive #5: 11110111 (Hot Spare) Drive #6: 11100110 (Parity)
At this point the dead drive has to be replaced with a working one of the same size. Depending on the implementation, the new drive either takes over as a new hot spare drive and the old hot spare drive continues to act as a data drive of the array, or (as illustrated below) the original hot spare's contents are automatically copied to the new drive by the array controller, allowing the original hot spare to return to its original purpose as an emergency standby drive. The resulting array is identical to its pre-failure state:
Drive #1: 00101010 (Data) Drive #2: 10001110 (Data) Drive #3: 11110111 (Data) Drive #4: 10110101 (Data) Drive #5: -------- (Hot Spare) Drive #6: 11100110 (Parity)
This same basic XOR principle applies to parity within RAID groups regardless of capacity or number of drives. As long as there are enough drives present to allow for an XOR calculation to take place, parity can be used to recover data from any single drive failure. (A minimum of three drives must be present in order for parity to be used for fault tolerance, because the XOR operator requires two operands, and a place to store the result).
RAID 10 versus RAID 5 in Relational Databases
A common opinion (and one which serves to illustrate the dynamics of proper RAID deployment) is that RAID 10 is inherently better for relational databases than RAID 5, because RAID 5 requires the recalculation and redistribution of parity data on a per-write basis.[10]
While this may have been a hurdle in past RAID 5 implementations, the task of parity recalculation and redistribution within modern Storage Area Network (SAN) appliances is performed as a back-end process transparent to the host, not as an in-line process which competes with existing I/O. (i.e. the RAID controller handles this as a housekeeping task to be performed during a particular spindle's idle timeslices, so as not to disrupt any pending I/O from the host.) The "write penalty" inherent to RAID 5 has been effectively masked since the late 1990s by a combination of improved controller design, larger amounts of cache, and faster drives. The effect of a write penalty when using RAID 5 is mostly a concern when the workload cannot be destaged efficiently from the SAN controller's write cache.
In some of enterprise-level SAN hardware, any writes which are generated by the host are simply stored in a small, mirrored NVRAM cache, such as an SSD drive, acknowledged faster than waiting for the write to go to disk, and finally synchronized with drives when the controller sees fit to do so from an efficiency standpoint. From the host's perspective, an individual write to a RAID 10 volume is no faster than an individual write to a RAID 5 volume, given sufficient amount of write cache; a difference between them becomes apparent when the write cache at the SAN controller level is overwhelmed, so that the SAN appliance must reject or gate further write requests. SAN appliances generally service multiple hosts that compete both for controller cache, potential SSD cache, and spindle time.
The choice between RAID 10 and RAID 5 for the purpose of housing a relational database depends upon a number of factors (spindle availability, cost, business risk, etc.) but, from a performance standpoint, it depends mostly on the type of I/O expected for a particular database application. For databases that are expected to be exclusively or strongly read-biased, RAID 10 is often chosen because it offers a slight speed improvement over RAID 5 on sustained reads and sustained randomized writes. If a database is expected to be strongly write-biased, RAID 5 becomes the more attractive option, since RAID 5 does not suffer from the same write handicap inherent in RAID 10; all spindles in a RAID 5 can be utilized to write simultaneously, whereas only half the members of a RAID 10 can be used.[11] However, for reasons similar to what has eliminated the "read penalty" in RAID 5, the 'write penalty' of RAID 10 has been largely masked by improvements in controller cache efficiency and drive throughput.
What causes RAID 5 to be slightly slower than RAID 10 on sustained reads is the fact that RAID 5 has parity data interleaved within normal data. For every read pass in RAID 5, there is a probability that a read head may need to traverse a region of parity data. The cumulative effect of this is a slight performance drop compared to RAID 10, which does not use parity, and therefore never encounters a circumstance where data underneath a head is of no use. For the vast majority of situations, however, most relational databases housed on RAID 10 perform equally well in RAID 5. The strengths and weaknesses of each type only become an issue in atypical deployments, or deployments on overcommitted hardware. Often, any measurable differences between the two formats are masked by structural deficiencies at the host layer, such as poor database maintenance, or sub-optimal I/O configuration settings.[12]
There are, however, other considerations which must be taken into account other than simply those regarding performance. RAID 5 and other non-mirror-based arrays offer a lower degree of resiliency than RAID 10 by virtue of RAID 10's mirroring strategy. In a RAID 10, I/O can continue even in spite of multiple drive failures. By comparison, in a RAID 5 array, any failure involving more than one drive renders the array itself unusable by virtue of parity recalculation being impossible to perform. Thus, RAID 10 is frequently favored because it provides the lowest level of risk.[11]
Additionally, the time required to rebuild data on a hot spare in a RAID 10 is significantly less than in a RAID 5, because all the remaining spindles in a RAID 5 rebuild must participate in the process, whereas only the hot spare and one mirror are required in a RAID 10. Thus, in comparison to a RAID 5, a RAID 10 has a smaller window of opportunity during which a second drive failure could cause array failure.
Modern SAN design largely masks any performance hit while a RAID is in a degraded state, by virtue of being able to perform rebuild operations both in-band or out-of-band with respect to existing I/O traffic. Given the rare nature of drive failures in general, and the exceedingly low probability of multiple concurrent drive failures occurring within the same RAID, the choice of RAID 5 over RAID 10 often comes down to the preference of the storage administrator, particularly when weighed against other factors such as cost, throughput requirements, and physical spindle availability.[11]
In short, the choice between RAID 5 and RAID 10 involves a complicated mixture of factors. There is no one-size-fits-all solution, as the choice of one over the other must be dictated by everything from the I/O characteristics of the database, to business risk, to worst case degraded-state throughput, to the number and type of drives present in the array itself. Over the course of the life of a database, one may even see situations where RAID 5 is initially favored, but RAID 10 slowly becomes the better choice, and vice versa.
New RAID classification
In 1996, the RAID Advisory Board introduced an improved classification of RAID systems. It divides RAID into three types:
- Failure-resistant (systems that protect against loss of data due to drive failure).
- Failure-tolerant (systems that protect against loss of data access due to failure of any single component).
- Disaster-tolerant (systems that consist of two or more independent zones, either of which provides access to stored data).
The original "Berkeley" RAID classifications are still kept as an important historical reference point and also to recognize that RAID Levels 0–6 successfully define all known data mapping and protection schemes for disk-based storage systems. Unfortunately, the original classification caused some confusion due to the assumption that higher RAID levels imply higher redundancy and performance; this confusion has been exploited by RAID system manufacturers, and it has given birth to the products with such names as RAID-7, RAID-10, RAID-30, RAID-S, etc. Consequently, the new classification describes the data availability characteristics of a RAID system, leaving the details of its implementation to system manufacturers.
- Failure-resistant disk systems (FRDS) (meets a minimum of criteria 1–6)
- Protection against data loss and loss of access to data due to drive failure
- Reconstruction of failed drive content to a replacement drive
- Protection against data loss due to a "write hole"
- Protection against data loss due to host and host I/O bus failure
- Protection against data loss due to replaceable unit failure
- Replaceable unit monitoring and failure indication
- Failure-tolerant disk systems (FTDS) (meets a minimum of criteria 1–15)
- Disk automatic swap and hot swap
- Protection against data loss due to cache failure
- Protection against data loss due to external power failure
- Protection against data loss due to a temperature out of operating range
- Replaceable unit and environmental failure warning
- Protection against loss of access to data due to device channel failure
- Protection against loss of access to data due to controller module failure
- Protection against loss of access to data due to cache failure
- Protection against loss of access to data due to power supply failure
- Disaster-tolerant disk systems (DTDS) (meets a minimum of criteria 1–21)
- Protection against loss of access to data due to host and host I/O bus failure
- Protection against loss of access to data due to external power failure
- Protection against loss of access to data due to component replacement
- Protection against loss of data and loss of access to data due to multiple drive failures
- Protection against loss of access to data due to zone failure
- Long-distance protection against loss of data due to zone failure
Non-standard levels
Many configurations other than the basic numbered RAID levels are possible, and many companies, organizations, and groups have created their own non-standard configurations, in many cases designed to meet the specialised needs of a small niche group. Most of these non-standard RAID levels are proprietary.
- Storage Computer Corporation used to call a cached version of RAID 3 and 4, RAID 7. Storage Computer Corporation is now defunct.
- EMC Corporation used to offer RAID S as an alternative to RAID 5 on their Symmetrix systems. Their latest generations of Symmetrix, the DMX and the V-Max series, do not support RAID S (instead they support RAID 1, RAID 5 and RAID 6.)
- The ZFS filesystem, available in Solaris, OpenSolaris and FreeBSD, offers RAID-Z, which solves RAID 5's write hole problem.
- Hewlett-Packard's Advanced Data Guarding (ADG) is a form of RAID 6.
- NetApp's Data ONTAP uses RAID-DP (also referred to as "double", "dual", or "diagonal" parity), is a form of RAID 6, but unlike many RAID 6 implementations, it does not use distributed parity as in RAID 5. Instead, two unique parity drives with separate parity calculations are used. This is a modification of RAID 4 with an extra parity drive.
- Accusys Triple Parity (RAID TP) implements three independent parities by extending RAID 6 algorithms on its FC-SATA and SCSI-SATA RAID controllers to tolerate a failure of 3 drives.
- Linux MD RAID10 (RAID 10) implements a general RAID driver that defaults to a standard RAID 1 with 2 drives, and a standard RAID 1+0 with four drives, but can have any number of drives, including odd numbers. MD RAID 10 can run striped and mirrored, even with only two drives with the f2 layout (mirroring with striped reads, giving the read performance of RAID 0; normal Linux software RAID 1 does not stripe reads, but can read in parallel).[8][13][14]
- Hewlett-Packard's EVA series arrays implement vRAID - vRAID-0, vRAID-1, vRAID-5, and vRAID-6; vRAID levels are closely aligned to Nested RAID levels: vRAID-1 is actually a RAID 1+0 (or RAID 10), vRAID-5 is actually a RAID 5+0 (or RAID 50), etc.
- IBM (among others) has implemented a RAID 1E (Level 1 Enhanced). It requires a minimum of 3 drives. It is similar to a RAID 1+0 array, but it can also be implemented with either an even or odd number of drives. The total available RAID storage is n/2.
- Hadoop has a RAID system that generates a parity file by xor-ing a stripe of blocks in a single HDFS file.[15]
Data backup
A RAID system used as secondary storage is not an alternative to backing up data. In parity configurations, a RAID protects from catastrophic data loss caused by physical damage or errors on a single drive within the array (or two drives in, say, RAID 6). However, a true backup system has other important features such as the ability to restore an earlier version of data, which is needed both to protect against software errors that write unwanted data to secondary storage, and also to recover from user error and malicious data deletion. A RAID can be overwhelmed by catastrophic failure that exceeds its recovery capacity and, of course, the entire array is at risk of physical damage by fire, natural disaster, and human forces, while backups can be stored off-site. A RAID is also vulnerable to controller failure because it is not always possible to migrate a RAID to a new, different controller without data loss.[16]
Implementations
The distribution of data across multiple drives can be managed either by dedicated hardware or by software. A software solution may be part of the operating system, or it may be part of the firmware and drivers supplied with a hardware RAID controller.
Software-based RAID
Software RAID implementations are now provided by many operating systems. Software RAID can be implemented as:
- a layer that abstracts multiple devices, thereby providing a single virtual device (e.g. Linux's md).
- a more generic logical volume manager (provided with most server-class operating systems, e.g. Veritas or LVM).
- a component of the file system (e.g. ZFS or Btrfs).
Volume manager support
Server class operating systems typically provide logical volume management, which allows a system to use logical volumes which can be resized or moved. Often, features like RAID or snapshots are also supported.
- Vinum is a logical volume manager supporting RAID-0, RAID-1, and RAID-5. Vinum is part of the base distribution of the FreeBSD operating system, and versions exist for NetBSD, OpenBSD, and DragonFly BSD.
- Solaris SVM supports RAID 1 for the boot filesystem, and adds RAID 0 and RAID 5 support (and various nested combinations) for data drives.
- Linux LVM supports RAID 0 and RAID 1.
- HP's OpenVMS provides a form of RAID 1 called "Volume shadowing", giving the possibility to mirror data locally and at remote cluster systems.
File system support
Some advanced file systems are designed to organize data across multiple storage devices directly (without needing the help of a third-party logical volume manager).
- ZFS supports equivalents of RAID 0, RAID 1, RAID 5 (RAID Z), RAID 6 (RAID Z2), and a triple parity version RAID Z3, and any nested combination of those like 1+0. ZFS is the native file system on Solaris, and also available on FreeBSD.
- Btrfs supports RAID 0, RAID 1, and RAID 10 (RAID 5 and 6 are under development).
Other support
Many operating systems provide basic RAID functionality independently of volume management.
- Apple's Mac OS X Server[17] and Mac OS X[18] support RAID 0, RAID 1, and RAID 1+0.
- FreeBSD supports RAID 0, RAID 1, RAID 3, and RAID 5, and all nestings via GEOM modules[19][20] and ccd.[21]
- Linux's md supports RAID 0, RAID 1, RAID 4, RAID 5, RAID 6, and all nestings.[22][23] Certain reshaping/resizing/expanding operations are also supported.[24]
- Microsoft's server operating systems support RAID 0, RAID 1, and RAID 5. Some of the Microsoft desktop operating systems support RAID such as Windows XP Professional which supports RAID level 0 in addition to spanning multiple drives but only if using dynamic disks and volumes. Windows XP can be modified to support RAID 0, 1, and 5.[25]
- NetBSD supports RAID 0, RAID 1, RAID 4, and RAID 5, and all nestings via its software implementation, named RAIDframe.
- OpenBSD aims to support RAID 0, RAID 1, RAID 4, and RAID 5 via its software implementation softraid.
- FlexRAID (for Linux and Windows) is a snapshot RAID implementation.
Software RAID has advantages and disadvantages compared to hardware RAID. The software must run on a host server attached to storage, and the server's processor must dedicate processing time to run the RAID software; the additional processing capacity required for RAID 0 and RAID 1 is low, but parity-based arrays require more complex data processing during write or integrity-checking operations. As the rate of data processing increases with the number of drives in the array, so does the processing requirement. Furthermore, all the buses between the processor and the drive controller must carry the extra data required by RAID, which may cause congestion.
Fortunately, over time, the increase in commodity CPU speed has been consistently greater than the increase in drive throughput;[26] the percentage of host CPU time required to saturate a given number of drives has decreased. For instance, under 100% usage of a single core on a 2.1 GHz Intel "Core2" CPU, the Linux software RAID subsystem (md) as of version 2.6.26 is capable of calculating parity information at 6 GB/s; however, a three-drive RAID 5 array using drives capable of sustaining a write operation at 100 MB/s only requires parity to be calculated at the rate of 200 MB/s, which requires the resources of just over 3% of a single CPU core.
Furthermore, software RAID implementations may employ more sophisticated algorithms than hardware RAID implementations (e.g. drive scheduling and command queueing), and thus, may be capable of better performance.
Another concern with software implementations is the process of booting the associated operating system. For instance, consider a computer being booted from a RAID 1 (mirrored drives); if the first drive in the RAID 1 fails, then a first-stage boot loader might not be sophisticated enough to attempt loading the second-stage boot loader from the second drive as a fallback. In contrast, a RAID 1 hardware controller typically has explicit programming to decide that a drive has malfunctioned and that the next drive should be used. At least the following second-stage boot loaders are capable of loading a kernel from a RAID 1:
- LILO (for Linux).
- Some configurations of the GRUB.
- The boot loader for FreeBSD.[27]
- The boot loader for NetBSD.
For data safety, the write-back cache of an operating system or individual drive might need to be turned off in order to ensure that as much data as possible is actually written to secondary storage before some failure (such as a loss of power); unfortunately, turning off the write-back cache has a performance penalty that can be significant depending on the workload and command queuing support. In contrast, a hardware RAID controller may carry a dedicated battery-powered write-back cache of its own, thereby allowing for efficient operation that is also relatively safe. Fortunately, it is possible to avoid such problems with a software controller by constructing a RAID with safer components; for instance, each drive could have its own battery or capacitor on its own write-back cache, and the drive could implement atomicity in various ways, and the entire RAID or computing system could be powered by a UPS, etc.
Finally, a software RAID controller that is built into an operating system usually uses proprietary data formats and RAID levels, so an associated RAID usually cannot be shared between operating systems as part of a multi boot setup. However, such a RAID may be moved between computers that share the same operating system; in contrast, such mobility is more difficult when using a hardware RAID controller because both computers must provide compatible hardware controllers. Also, if the hardware controller fails, data could become unrecoverable unless a hardware controller of the same type is obtained.
Most software implementations allow a RAID to be created from partitions rather than entire physical drives. For instance, an administrator could divide each drive of an odd number of drives into two partitions, and then mirror partitions across drives and stripe a volume across the mirrored partitions to emulate IBM's RAID 1E configuration. Using partitions in this way also allows for constructing multiple RAIDs in various RAID levels from the same set of drives. For example, one could have a very robust RAID 1 for important files, and a less robust RAID 5 or RAID 0 for less important data, all using the same set of underlying drives. (Some BIOS-based controllers offer similar features, e.g. Intel Matrix RAID.) Using two partitions from the same drive in the same RAID puts data at risk if the drive fails; for instance:
- A RAID 1 across partitions from the same drive makes all the data inaccessible if the single drive fails.
- Consider a RAID 5 composed of 4 drives, 3 of which are 250 GB and one of which is 500 GB; the 500 GB drive is split into 2 partitions, each of which is 250 GB. Then, a failure of the 500 GB drive would remove 2 underlying 'drives' from the array, causing a failure of the entire array.
Hardware-based RAID
Hardware RAID controllers use proprietary data layouts, so it is not usually possible to span controllers from different manufacturers. They do not require processor resources, the BIOS can boot from them, and tighter integration with the device driver may offer better error handling.
On a desktop system, a hardware RAID controller may be an expansion card connected to a bus (e.g., PCI or PCIe), a component integrated into the motherboard; there are controllers for supporting most types of drive technology, such as IDE/ATA, SATA, SCSI, SSA, Fibre Channel, and sometimes even a combination. The controller and drives may be in a stand-alone enclosure, rather than inside a computer, and the enclosure may be directly attached to a computer, or connected via a SAN.
Most hardware implementations provide a read/write cache, which, depending on the I/O workload, improves performance. In most systems, the write cache is non-volatile (i.e. battery-protected), so pending writes are not lost in the event of a power failure.
Hardware implementations provide guaranteed performance, add no computational overhead to the host computer, and can support many operating systems; the controller simply presents the RAID as another logical drive.
Firmware/driver-based RAID
A RAID implemented at the level of an operating system is not always compatible with the system's boot process, and it is generally impractical for desktop versions of Windows (as described above). However, hardware RAID controllers are expensive and proprietary. To fill this gap, cheap "RAID controllers" were introduced that do not contain a dedicated RAID controller chip, but simply a standard drive controller chip with special firmware and drivers; during early stage bootup, the RAID is implemented by the firmware, and once the operating system has been more completely loaded, then the drivers take over control. Consequently, such controllers may not work when driver support is not available for the host operating system.[28]
Initially, the term "RAID controller" implied that the controller does the processing. However, while a controller without a dedicated RAID chip is often described by a manufacturer as a "RAID controller", it is rarely made clear that the burden of RAID processing is borne by a host computer's central processing unit rather than the RAID controller itself. Thus, this new type is sometimes called "fake" RAID; Adaptec calls it a "HostRAID".
Moreover, a firmware controller can often only support certain types of hard drive to form the RAID that it manages (e.g. SATA for an Intel Matrix RAID, as there is neither SCSI nor PATA support in modern Intel ICH southbridges; however, motherboard makers implement RAID controllers outside of the southbridge on some motherboards).
Hot spares
Both hardware and software RAIDs with redundancy may support the use of a hot spare drive; this is a drive physically installed in the array which is inactive until an active drive fails, when the system automatically replaces the failed drive with the spare, rebuilding the array with the spare drive included. This reduces the mean time to recovery (MTTR), but does not completely eliminate it. As with non-hot-spare systems, subsequent additional failure(s) in the same RAID redundancy group before the array is fully rebuilt can cause data loss. Rebuilding can take several hours, especially on busy systems.
It is sometimes considered that if drives are procured and installed at the same time, several drives are more likely to fail at about the same time than for unrelated drives, so rapid replacement of a failed drive is important. RAID 6 without a spare uses the same number of drives as RAID 5 with a hot spare and protects data against failure of up to two drives, but requires a more advanced RAID controller. Further, a hot spare can be shared by multiple RAID sets.
Data scrubbing
Data scrubbing is periodic reading and checking by the RAID controller of all the blocks in a RAID, including those not otherwise accessed. This allows bad blocks to be detected before they are used.[29]
Reliability terms
- Failure rate
- Two different kinds of failure rates are applicable to RAID systems. Logical failure is defined as the loss of a single drive and its rate is equal to the sum of individual drives' failure rates. System failure is defined as loss of data and its rate will depend on the type of RAID. For RAID 0 this is equal to the logical failure rate, as there is no redundancy. For other types of RAID, it will be less than the logical failure rate, potentially very small, and its exact value will depend on the type of RAID, the number of drives employed, the vigilance and alacrity of its human administrators, and chance (improbable events do occur, though infrequently).
- Mean time to data loss (MTTDL)
- In this context, the average time before a loss of data in a given array.[30] Mean time to data loss of a given RAID may be higher or lower than that of its constituent hard drives, depending upon what type of RAID is employed. The referenced report assumes times to data loss are exponentially distributed, so that 63.2% of all data loss will occur between time 0 and the MTTDL.
- Mean time to recovery (MTTR)
- In arrays that include redundancy for reliability, this is the time following a failure to restore an array to its normal failure-tolerant mode of operation. This includes time to replace a failed drive mechanism and time to re-build the array (to replicate data for redundancy).
- Unrecoverable bit error rate (UBE)
- This is the rate at which a drive will be unable to recover data after application of cyclic redundancy check (CRC) codes and multiple retries.
- Write cache reliability
- Some RAID systems use RAM write cache to increase performance. A power failure can result in data loss unless this sort of drive buffer has a supplementary battery to ensure that the buffer has time to write from RAM to secondary storage before the drive powers down.
- Atomic write failure
- Also known by various terms such as torn writes, torn pages, incomplete writes, interrupted writes, non-transactional, etc.
Problems with RAID
The theory behind the error correction in RAID assumes that failures of drives are independent. Given these assumptions, it is possible to calculate how often they can fail and to arrange the array to make data loss arbitrarily improbable. There is also an assumption that motherboard failures won't damage the harddrive and that harddrive failures occure more often than motherboard failures.
In practice, the drives are often the same age (with similar wear) and subject to the same environment. Since many drive failures are due to mechanical issues (which are more likely on older drives), this violates those assumptions; failures are in fact statistically correlated. In practice, the chances of a second failure before the first has been recovered (causing data loss) is not as unlikely as for random failures. In a study including about 100 thousand drives, the probability of two drives in the same cluster failing within one hour was observed to be four times larger than was predicted by the exponential statistical distribution which characterises processes in which events occur continuously and independently at a constant average rate. The probability of two failures within the same 10-hour period was twice as large as that which was predicted by an exponential distribution.[31]
A common assumption is that "server-grade" drives fail less frequently than consumer-grade drives. Two independent studies (one by Carnegie Mellon University and the other by Google) have shown that the "grade" of a drive does not relate to the drive's failure rate.[32][33]
In addition, there is no protection circuitry between the motherboard and harddrive electronics, so a catastrophic failure of the motherboard can cause the harddrive electronics to fail. Therefore, taking elaborate precautions via RAID setups ignores the equal risk of electronics failures elsewhere which can cascade to a harddrive failure. For a robust critical data system, no risk can outweigh another as the consequence of any data loss is unacceptable.
Atomicity
This is a little understood and rarely mentioned failure mode for redundant storage systems that do not utilize transactional features. Database researcher Jim Gray wrote "Update in Place is a Poison Apple"[34] during the early days of relational database commercialization. However, this warning largely went unheeded and fell by the wayside upon the advent of RAID, which many software engineers mistook as solving all data storage integrity and reliability problems. Many software programs update a storage object "in-place"; that is, they write a new version of the object on to the same secondary storage addresses as the old version of the object. While the software may also log some delta information elsewhere, it expects the storage to present "atomic write semantics," meaning that the write of the data either occurred in its entirety or did not occur at all.
However, very few storage systems provide support for atomic writes, and even fewer specify their rate of failure in providing this semantic. Note that during the act of writing an object, a RAID storage device will usually be writing all redundant copies of the object in parallel, although overlapped or staggered writes are more common when a single RAID processor is responsible for multiple drives. Hence an error that occurs during the process of writing may leave the redundant copies in different states, and furthermore may leave the copies in neither the old nor the new state. The little known failure mode is that delta logging relies on the original data being either in the old or the new state so as to enable backing out the logical change, yet few storage systems provide an atomic write semantic for a RAID.
While the battery-backed write cache may partially solve the problem, it is applicable only to a power failure scenario.
Since transactional support is not universally present in hardware RAID, many operating systems include transactional support to protect against data loss during an interrupted write. Novell NetWare, starting with version 3.x, included a transaction tracking system. Microsoft introduced transaction tracking via the journaling feature in NTFS. ext4 has journaling with checksums; ext3 has journaling without checksums but an "append-only" option, or ext3cow (Copy on Write). If the journal itself in a filesystem is corrupted though, this can be problematic. The journaling in NetApp WAFL file system gives atomicity by never updating the data in place, as does ZFS. An alternative method to journaling is soft updates, which are used in some BSD-derived system's implementation of UFS.
This can present as a sector read failure. Some RAID implementations protect against this failure mode by remapping the bad sector, using the redundant data to retrieve a good copy of the data, and rewriting that good data to the newly mapped replacement sector. The UBE (Unrecoverable Bit Error) rate is typically specified at 1 bit in 1015 for enterprise class drives (SCSI, FC, SAS) , and 1 bit in 1014 for desktop class drives (IDE/ATA/PATA, SATA). Increasing drive capacities and large RAID 5 redundancy groups have led to an increasing inability to successfully rebuild a RAID group after a drive failure because an unrecoverable sector is found on the remaining drives. Double protection schemes such as RAID 6 are attempting to address this issue, but suffer from a very high write penalty.
Write cache reliability
The drive system can acknowledge the write operation as soon as the data is in the cache, not waiting for the data to be physically written. This typically occurs in old, non-journaled systems such as FAT32, or if the Linux/Unix "writeback" option is chosen without any protections like the "soft updates" option (to promote I/O speed whilst trading-away data reliability). A power outage or system hang such as a BSOD can mean a significant loss of any data queued in such a cache.
Often a battery is protecting the write cache, mostly solving the problem. If a write fails because of power failure, the controller may complete the pending writes as soon as restarted. This solution still has potential failure cases: the battery may have worn out, the power may be off for too long, the drives could be moved to another controller, and the controller itself could fail. Some systems provide the capability of testing the battery periodically, however this leaves the system without a fully charged battery for several hours.
An additional concern about write cache reliability exists, specifically regarding devices equipped with a write-back cache—a caching system which reports the data as written as soon as it is written to cache, as opposed to the non-volatile medium.[35] The safer cache technique is write-through, which reports transactions as written when they are written to the non-volatile medium.
Equipment compatibility
The methods used to store data by various RAID controllers are not necessarily compatible, so that it may not be possible to read a RAID on different hardware, with the exception of RAID 1, which is typically represented as plain identical copies of the original data on each drive. Consequently a non-drive hardware failure may require the use of identical hardware to recover the data, and furthermore an identical configuration has to be reassembled without triggering a rebuild and overwriting the data. Software RAID however, such as implemented in the Linux kernel, alleviates this concern, as the setup is not hardware dependent, but runs on ordinary drive controllers, and allows the reassembly of an array. Additionally, individual drives of a RAID 1 (software and most hardware implementations) can be read like normal drives when removed from the array, so no RAID system is required to retrieve the data. Inexperienced data recovery firms typically have a difficult time recovering data from RAID drives, with the exception of RAID1 drives with conventional data structure.
Data recovery in the event of a failed array
With larger drive capacities the odds of a drive failure during rebuild are not negligible. In that event, the difficulty of extracting data from a failed array must be considered. Only a RAID 1 (mirror) stores all data on each drive in the array. Although it may depend on the controller, some individual drives in a RAID 1 can be read as a single conventional drive; this means a damaged RAID 1 can often be easily recovered if at least one component drive is in working condition. If the damage is more severe, some or all data can often be recovered by professional data recovery specialists. However, other RAID levels (like RAID level 5) present much more formidable obstacles to data recovery.
Drive error recovery algorithms
Many modern drives have internal error recovery algorithms that can take upwards of a minute to recover and re-map data that the drive fails to read easily. Frequently, a RAID controller is configured to drop a component drive (that is, to assume a component drive has failed) if the drive has been unresponsive for 8 seconds or so; this might cause the array controller to drop a good drive because that drive has not been given enough time to complete its internal error recovery procedure. Consequently, desktop drives can be quite risky when used in a RAID, and so-called enterprise class drives limit this error recovery time in order to obviate the problem.
A fix specific to Western Digital's desktop drives used to be known: A utility called WDTLER.exe could limit a drive's error recovery time; the utility enabled TLER (time limited error recovery), which limits the error recovery time to 7 seconds. Around September 2009, Western Digital disabled this feature in their desktop drives (e.g., the Caviar Black line), making such drives unsuitable for use in a RAID.[36]
However, Western Digital enterprise class drives are shipped from the factory with TLER enabled. Similar technologies are used by Seagate, Samsung, and Hitachi. Of course, for non-RAID usage, an enterprise class drive with a short error recovery timeout that cannot be changed is therefore less suitable than a desktop drive.[36].
In late 2010, the Smartmontools program began supporting the configuration of ATA Error Recovery Control, allowing the tool to configure many desktop class hard drives for use in a RAID.[36]
Recovery time is increasing
Drive capacity has grown at a much faster rate than transfer speed, and error rates have only fallen a little in comparison. Therefore, larger capacity drives may take hours, if not days, to rebuild. The re-build time is also limited if the entire array is still in operation at reduced capacity.[37] Given a RAID with only one drive of redundancy (RAIDs 3, 4, and 5), a second failure would cause complete failure of the array. Even though individual drives' mean time between failure (MTBF) have increased over time, this increase has not kept pace with the increased storage capacity of the drives. The time to rebuild the array after a single drive failure, as well as the chance of a second failure during a rebuild, have increased over time.[38]
Operator skills, correct operation
In order to provide the desired protection against physical drive failure, a RAID must be properly set up and maintained by an operator with sufficient knowledge of the chosen RAID configuration, array controller (hardware or software), failure detection and recovery. Unskilled handling of the array at any stage may exacerbate the consequences of a failure, and result in downtime and full or partial loss of data that might otherwise be recoverable.
Particularly, the array must be monitored, and any failures detected and dealt with promptly. Failure to do so will result in the array continuing to run in a degraded state, vulnerable to further failures. Ultimately more failures may occur, until the entire array becomes inoperable, resulting in data loss and downtime. In this case, any protection the array may provide merely delays this.
The operator must know how to detect failures or verify healthy state of the array, identify which drive failed, have replacement drives available, and know how to replace a drive and initiate a rebuild of the array.
Other problems
While RAID may protect against physical drive failure, the data is still exposed to operator, software, hardware and virus destruction. Many studies[39] cite operator fault as the most common source of malfunction, such as a server operator replacing the incorrect drive in a faulty RAID, and disabling the system (even temporarily) in the process.[40] Most well-designed systems include separate backup systems that hold copies of the data, but do not allow much interaction with it. Most copy the data and remove the copy from the computer for safe storage.
History
Norman Ken Ouchi at IBM was awarded a 1978 U.S. patent 4,092,732[41] titled "System for recovering data stored in failed memory unit." The claims for this patent describe what would later be termed RAID 5 with full stripe writes. This 1978 patent also mentions that drive mirroring or duplexing (what would later be termed RAID 1) and protection with dedicated parity (that would later be termed RAID 4) were prior art at that time.
The term RAID was first defined by David A. Patterson, Garth A. Gibson and Randy Katz at the University of California, Berkeley, in 1987. They studied the possibility of using two or more drives to appear as a single device to the host system and published a paper: "A Case for Redundant Arrays of Inexpensive Disks (RAID)" in June 1988 at the SIGMOD conference.[3]
This specification suggested a number of prototype RAID levels, or combinations of drives. Each had theoretical advantages and disadvantages. Over the years, different implementations of the RAID concept have appeared. Most differ substantially from the original idealized RAID levels, but the numbered names have remained. This can be confusing, since one implementation of RAID 5, for example, can differ substantially from another. RAID 3 and RAID 4 are often confused and even used interchangeably.
One of the early uses of RAID 0 and 1 was the Crosfield Electronics Studio 9500 page layout system based on the Python workstation. The Python workstation was a Crosfield managed international development using PERQ 3B electronics, benchMark Technology's Viper display system and Crosfield's own RAID and fibre-optic network controllers. RAID 0 was particularly important to these workstations as it dramatically sped up image manipulation for the pre-press markets. Volume production started in Peterborough, England in early 1987.
Non-RAID drive architectures
Non-RAID drive architectures also exist, and are often referred to, similarly to RAID, by standard acronyms, several tongue-in-cheek. A single drive is referred to as a SLED (Single Large Expensive Disk/Drive), by contrast with RAID, while an array of drives without any additional control (accessed simply as independent drives) is referred to, even in a formal context such as equipment specification, as a JBOD (Just a Bunch Of Disks). Simple concatenation is referred to as a "span".
See also
- Standard RAID levels
- Disk array controller
- Redundant Array of Inexpensive Nodes
- Redundant Array of Independent Memory (RAIM)
- Stable storage
- Hard drives
- Disk array
- Storage area network (SAN)
References
- ^ Donald, L. (2003), MCSA/MCSE 2003 JumpStart Computer and Network Basics (2nd ed.), Glasgow: SYBEX
- ^ Howe, Denis, ed., "Redundant Arrays of Independent Disks from FOLDOC", Free On-line Dictionary of Computing (Imperial College Department of Computing), http://foldoc.org/RAID, retrieved 2011-11-10
- ^ a b David A. Patterson, Garth Gibson, and Randy H. Katz: A Case for Redundant Arrays of Inexpensive Disks (RAID). University of California Berkeley. 1988.
- ^ "Originally referred to as Redundant Array of Inexpensive Disks, the concept of RAID was first developed in the late 1980s by Patterson, Gibson, and Katz of the University of California at Berkeley. (The RAID Advisory Board has since substituted the term Inexpensive with Independent.)" Storagecc Area Network Fundamentals; Meeta Gupta; Cisco Press; ISBN 978-1-58705-065-7; Appendix A.
- ^ See RAS syndrome.
- ^ "SNIA Dictionary". Snia.org. http://www.snia.org/education/dictionary. Retrieved 2010-08-24.
- ^ Vijayan, S.; Selvamani, S. ; Vijayan, S (1995). "Dual-Crosshatch Disk Array: A Highly Reliable Hybrid-RAID Architecture". Proceedings of the 1995 International Conference on Parallel Processing: Volume 1. CRC Press. pp. I–146ff. ISBN 084932615X. http://books.google.com/?id=QliANH5G3_gC&dq=%22hybrid+raid%22.
- ^ a b Jeffrey B. Layton: "Intro to Nested-RAID: RAID-01 and RAID-10", Linux Magazine, January 6, 2011
- ^ DAwkins, Bill and Jones, Arnold. "Common RAID Disk Data Format Specification" [Storage Networking Industry Association] Colorado Springs, 28 July 2006. Retrieved on 22 February 2011.
- ^ http://www.bytepile.com/raid_class.php#5
- ^ a b c http://www.bytepile.com/raid_class.php#10
- ^ http://www-03.ibm.com/systems/resources/systems_storage_disk_ess_pdf_raid5-raid10.pdf
- ^ [1], question 4
- ^ "Main Page - Linux-raid". Linux-raid.osdl.org. 2010-08-20. http://linux-raid.osdl.org/. Retrieved 2010-08-24.
- ^ "Hdfs Raid". Hadoopblog.blogspot.com. 2009-08-28. http://hadoopblog.blogspot.com/2009/08/hdfs-and-erasure-codes-hdfs-raid.html. Retrieved 2010-08-24.
- ^ "The RAID Migration Adventure". http://www.tomshardware.com/reviews/RAID-MIGRATION-ADVENTURE,1640.html. Retrieved 2010-03-10.
- ^ "Apple Mac OS X Server File Systems". http://www.apple.com/server/macosx/technology/file-system.html. Retrieved 2008-04-23.
- ^ "Mac OS X: How to combine RAID sets in Disk Utility". http://support.apple.com/kb/TA24359. Retrieved 2010-01-04.
- ^ "FreeBSD System Manager's Manual page for GEOM(8)". http://www.freebsd.org/cgi/man.cgi?query=geom. Retrieved 2009-03-19.
- ^ "freebsd-geom mailing list - new class / geom_raid5". http://lists.freebsd.org/pipermail/freebsd-geom/2006-July/001356.html. Retrieved 2009-03-19.
- ^ "FreeBSD Kernel Interfaces Manual for CCD(4)". http://www.freebsd.org/cgi/man.cgi?query=ccd. Retrieved 2009-03-19.
- ^ "The Software-RAID HOWTO". http://tldp.org/HOWTO/Software-RAID-HOWTO.html. Retrieved 2008-11-10.
- ^ "RAID setup". http://linux-raid.osdl.org/index.php/RAID_setup. Retrieved 2008-11-10.
- ^ "RAID setup". https://raid.wiki.kernel.org/index.php/RAID_setup. Retrieved 2010-09-30.
- ^ "Using WindowsXP to Make RAID 5 Happen". Tomshardware.com. http://www.tomshardware.com/reviews/windowsxp-make-raid-5-happen,925.html. Retrieved 2010-08-24.
- ^ "Rules of Thumb in Data Engineering". http://research.microsoft.com/pubs/68636/ms_tr_99_100_rules_of_thumb_in_data_engineering.pdf. Retrieved 2010-01-14.
- ^ "FreeBSD Handbook". Chapter 19 GEOM: Modular Disk Transformation Framework. http://www.freebsd.org/doc/en_US.ISO8859-1/books/handbook/geom-mirror.html. Retrieved 2009-03-19.
- ^ https://ata.wiki.kernel.org/index.php/SATA_RAID_FAQ
- ^ Ulf Troppens, Wolfgang Mueller-Friedt, Rainer Erkens, Rainer Wolafka, Nils Haustein. Storage Networks Explained: Basics and Application of Fibre Channel SAN, NAS, ISCSI,InfiniBand and FCoE. John Wiley and Sons, 2009. p.39
- ^ Jim Gray and Catharine van Ingen, "Empirical Measurements of Disk Failure Rates and Error Rates", MSTR-2005-166, December 2005
- ^ Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You? Bianca Schroeder and Garth A. Gibson
- ^ "Everything You Know About Disks Is Wrong". Storagemojo.com. 2007-02-22. http://storagemojo.com/2007/02/20/everything-you-know-about-disks-is-wrong/. Retrieved 2010-08-24.
- ^ Eduardo Pinheiro, Wolf-Dietrich Weber and Luiz André Barroso (February 2007). "Failure Trends in a Large Disk Drive Population". Google Inc. http://research.google.com/archive/disk_failures.pdf. Retrieved 2011-12-26.
- ^ Jim Gray: The Transaction Concept: Virtues and Limitations (Invited Paper) VLDB 1981: 144-154
- ^ "Definition of write-back cache at SNIA dictionary". http://www.snia.org/education/dictionary/w/.
- ^ a b c "Error recovery control with smartmontools". http://www.csc.liv.ac.uk/~greg/projects/erc/. Retrieved 2011.
- ^ Patterson, D., Hennessy, J. (2009). Computer Organization and Design. New York: Morgan Kaufmann Publishers. pp 604-605.
- ^ Newman, Henry (2009-09-17). "RAID's Days May Be Numbered". EnterpriseStorageForum. http://www.enterprisestorageforum.com/technology/features/article.php/3839636. Retrieved 2010-09-07.
- ^ These studies are: Gray, J (1990), Murphy and Gent (1995), Kuhn (1997), and Enriquez P. (2003). See following source.
- ^ Patterson, D., Hennessy, J. (2009), 574.
- ^ US patent 4092732, Norman Ken Ouchi, "System for recovering data stored in failed memory unit", issued 1978-05-30
Further reading
- Charles M. Kozierok (2001-04-17). "Redundant Arrays of Inexpensive Disks". The PC Guide. Pair Networks. http://pcguide.com/ref/hdd/perf/raid/index.htm.
- RAID Level 2
External links
- RAID at the Open Directory Project